Summary:
Complete guide to setting up AWS S3, and Athena for use with #RSTATS
AWS User Account Creation:
User Account Step 1:
- Log into AWS site and navigate to the IAM Management Console found under the (Security, Identity, & Compliance) section
- Next goto Users and Choose Add User
- Enter a name for the new user and select “Programmatic access” type
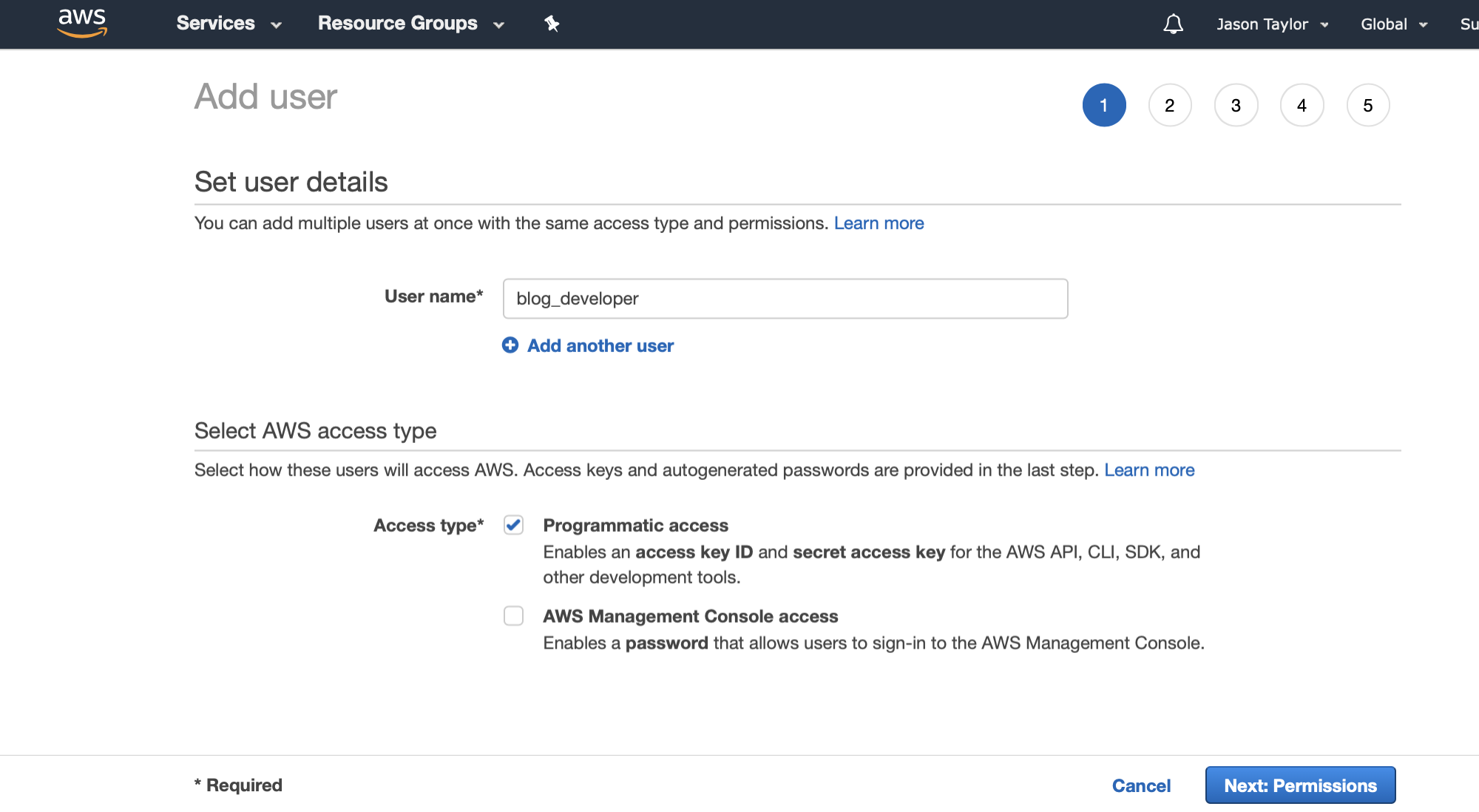
User Account Step 2:
Create a group so that you can assign the same permissions to additional users in the future
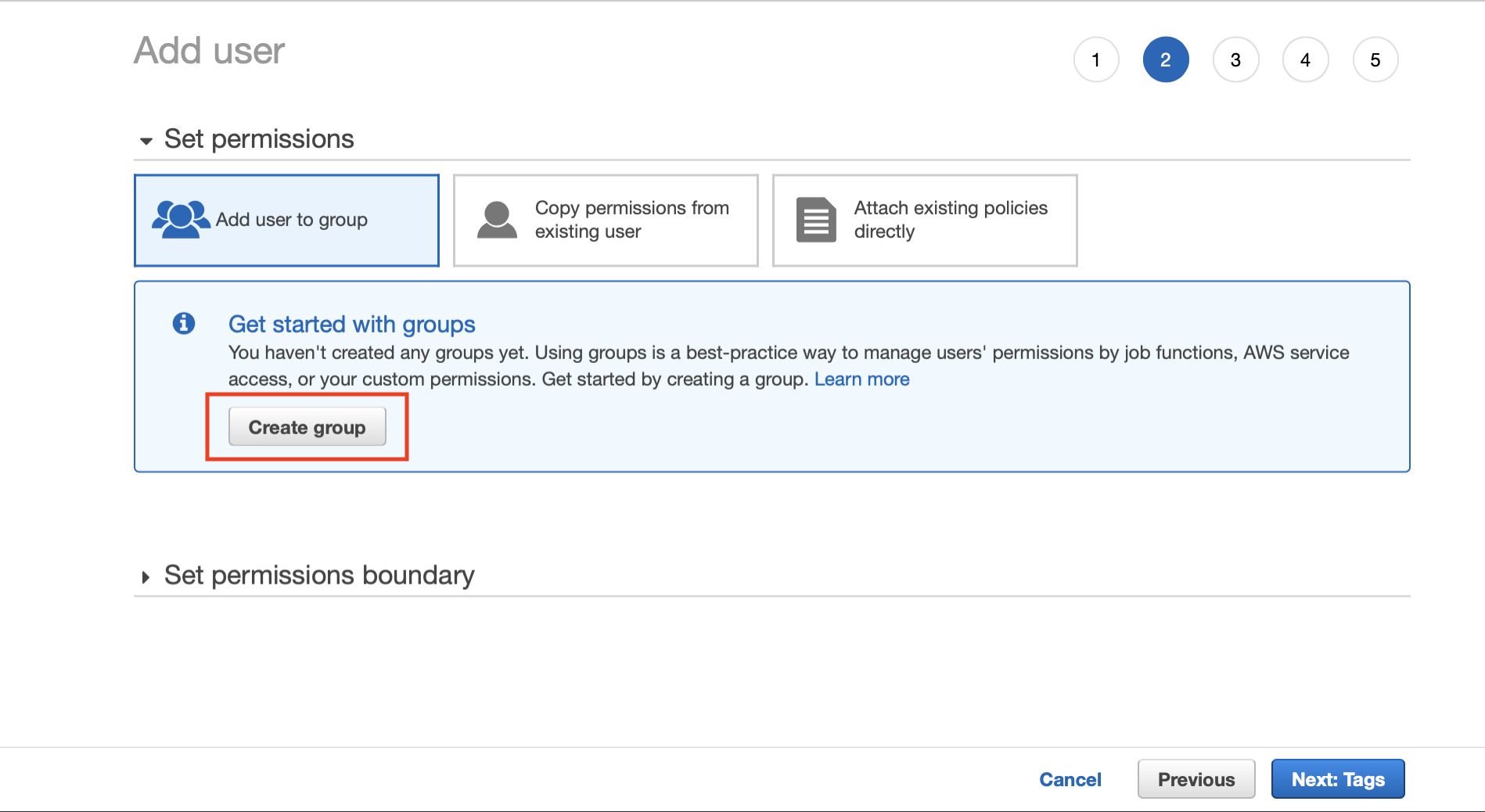
User Account Step 3:
- In this example I created a group named “blogger”
- Assign the following roles
- AWSQuicksightAthenaAccess
- AmazonS3FullAccess
- AmazonAthenaFullAccess
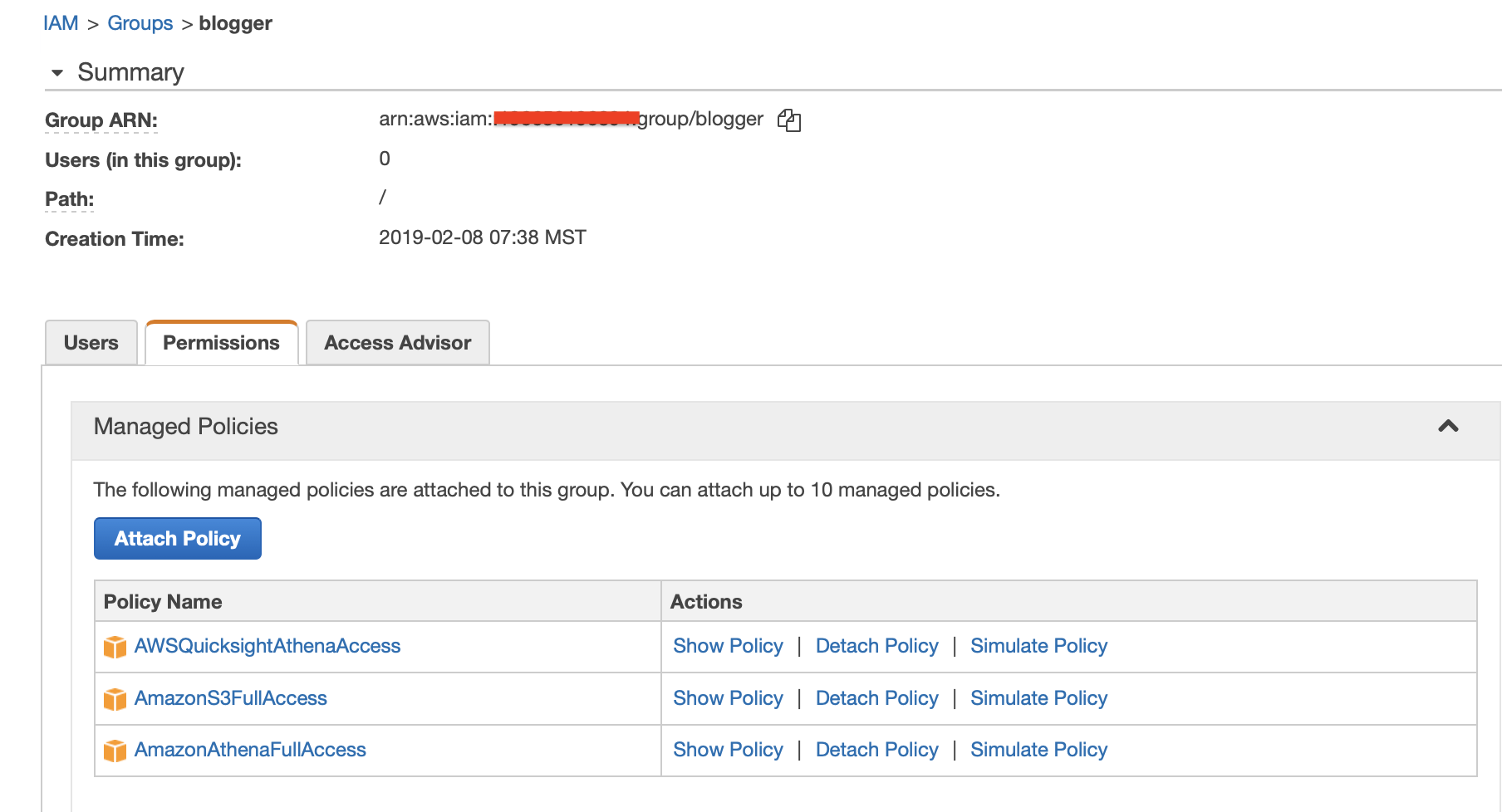
User Account Step 4:
Make sure to add the new user to the group you just created
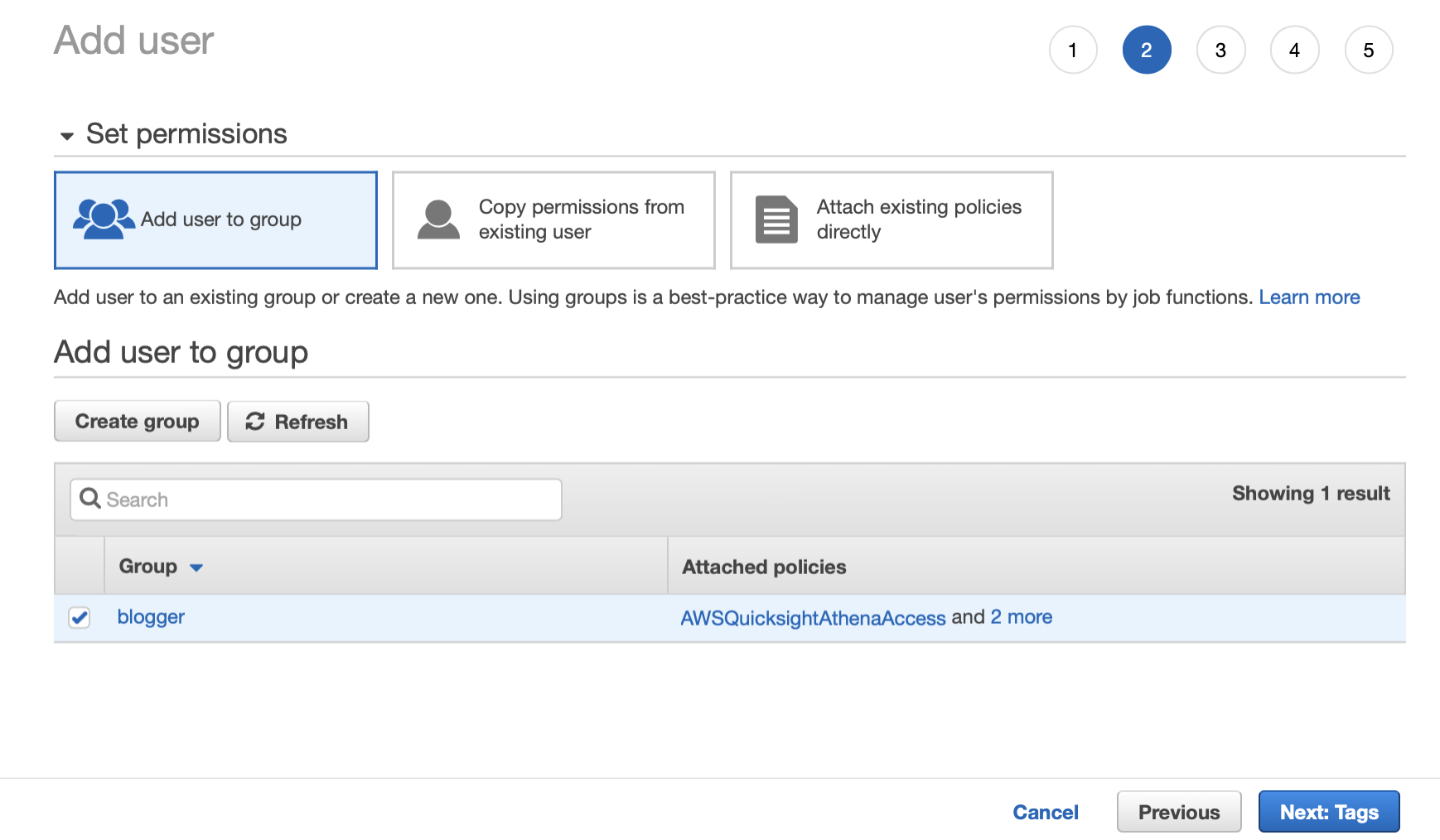
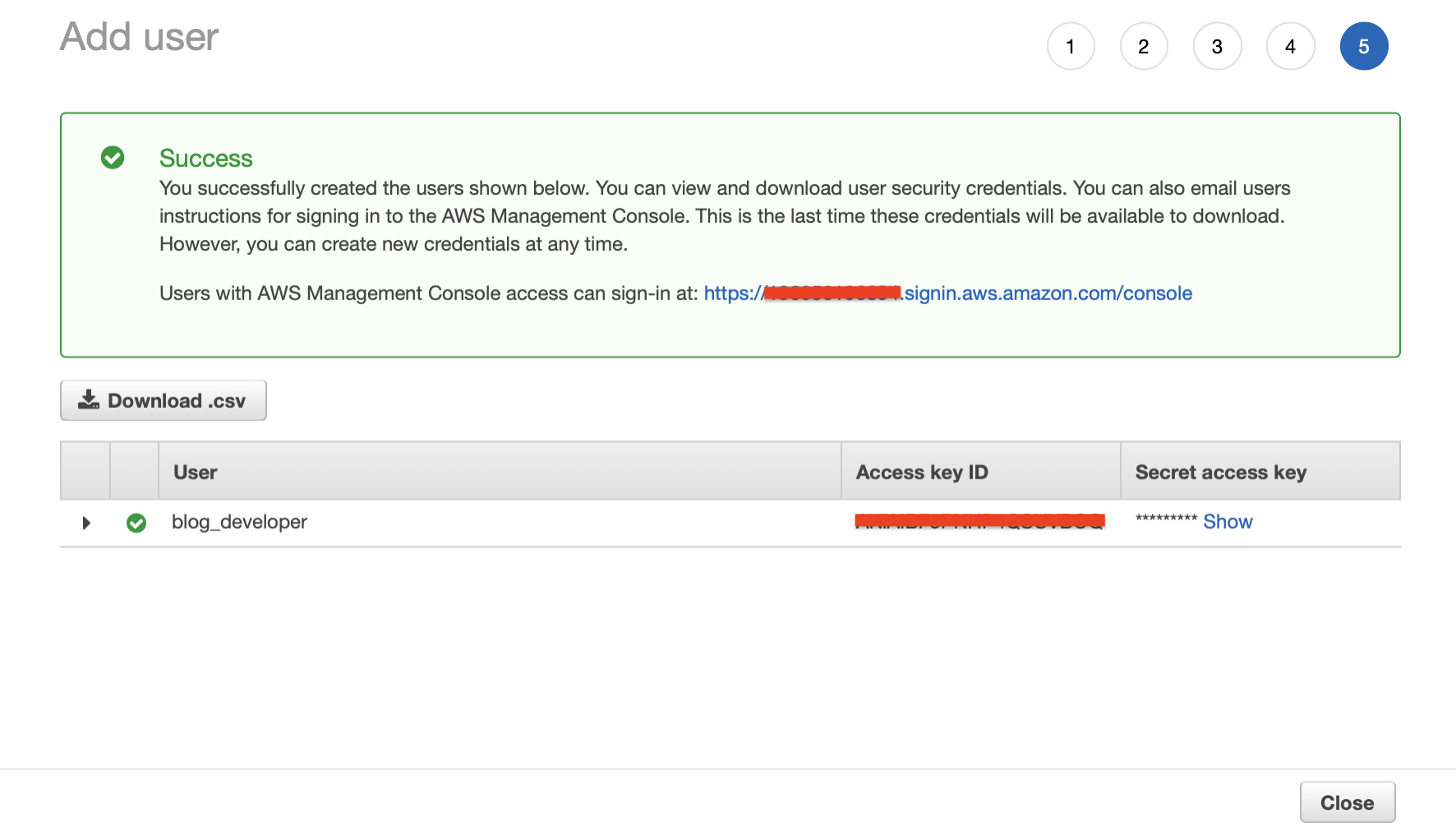
User Account Step 5:
- The last step #5 shows that you successfully created the new user and provides you with the accounts Access key ID and Secret access key
- Write these down the access key will be available in the user account details screen but the secret key is only shown here and will need to be reset once you leave this screen if you loose it.
AWS S3 bucket creation:
S3 Bucket Step 1:
- Navigate to the S3 Console found under the (Storage) section
- Choose create bucket

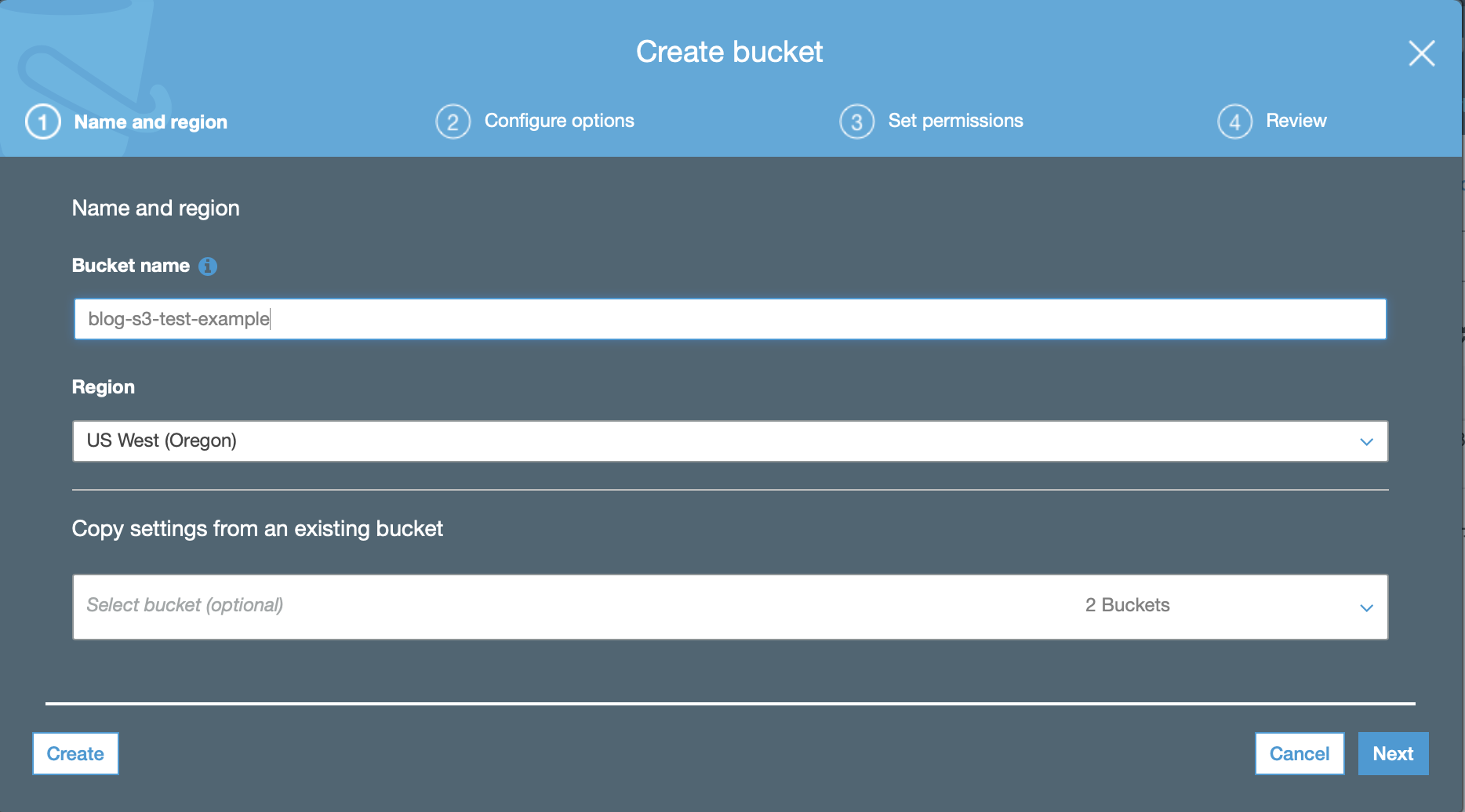
S3 Bucket Step 2:
- Give the bucket a unique and informative name
- Take note of the region you are working in in this case US West Oregon
- For the R configuration later this is “us-west-2”
S3 Bucket Step 3:
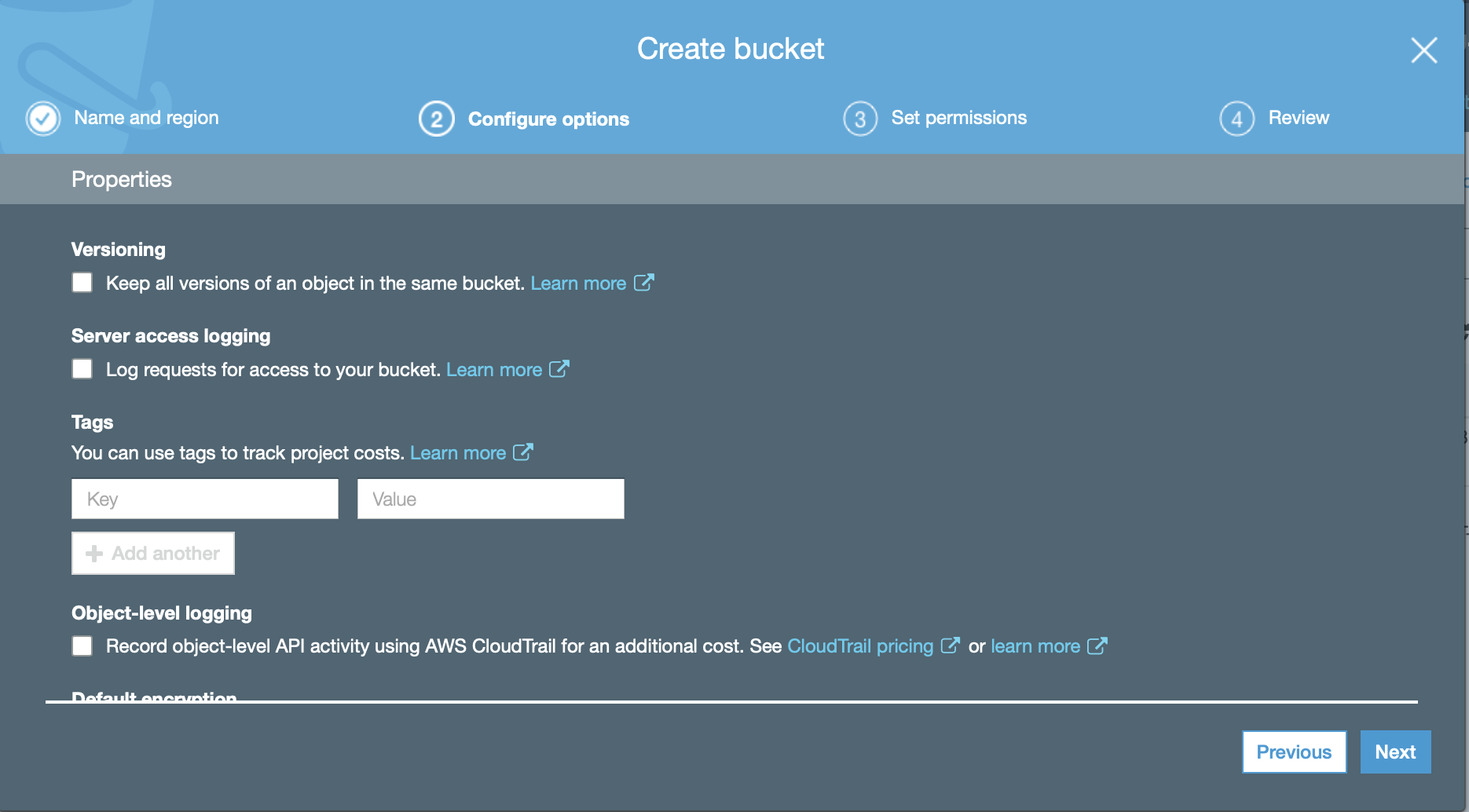
You can choose versioning, logs, etc, but I’ve left them all blank for this example
S3 Bucket Step 4:
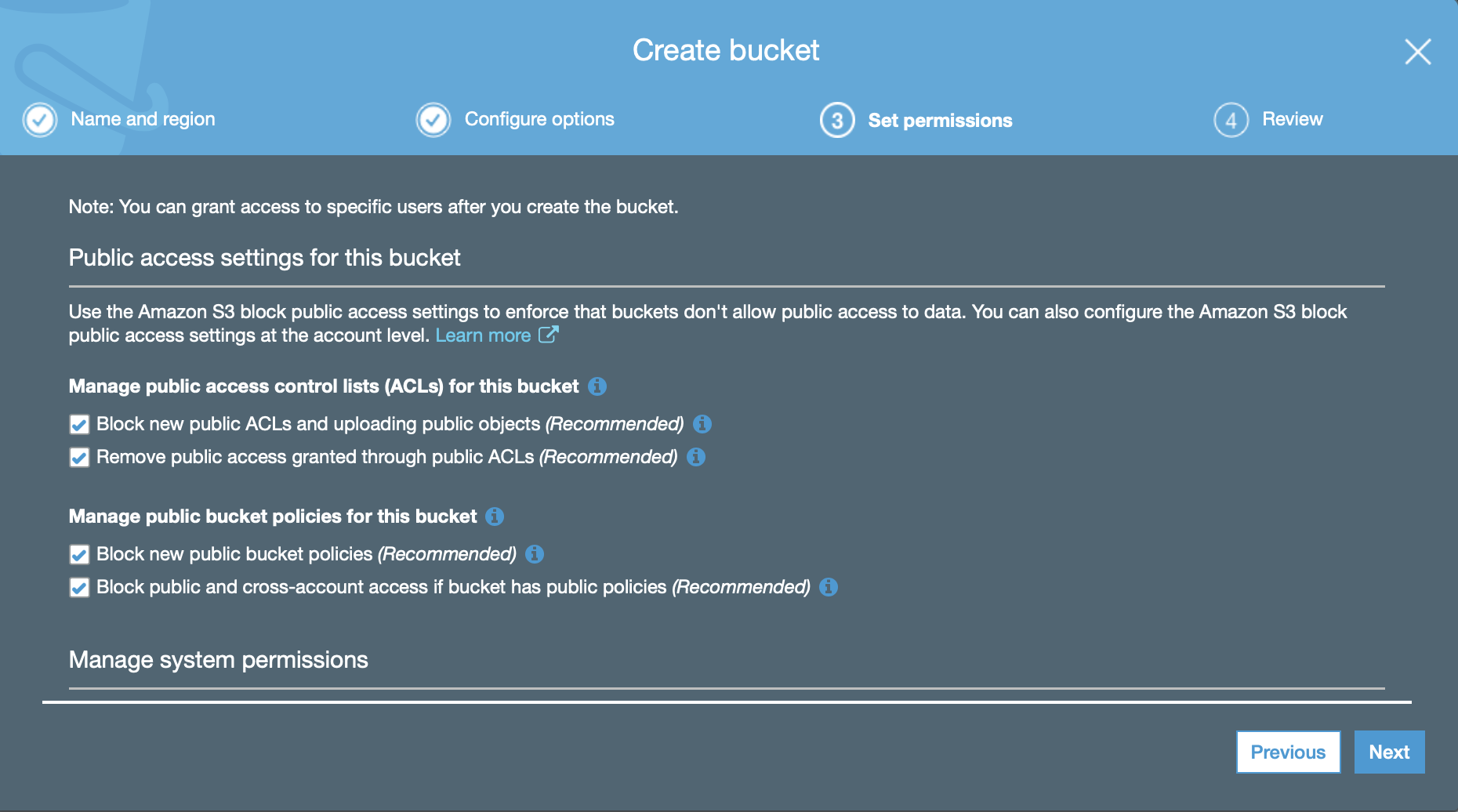
Enable the 4 check boxes for keeping the bucket private if they are not already set
S3 Bucket Step 5:
Review the settings you chose and click Create bucket to complete the process
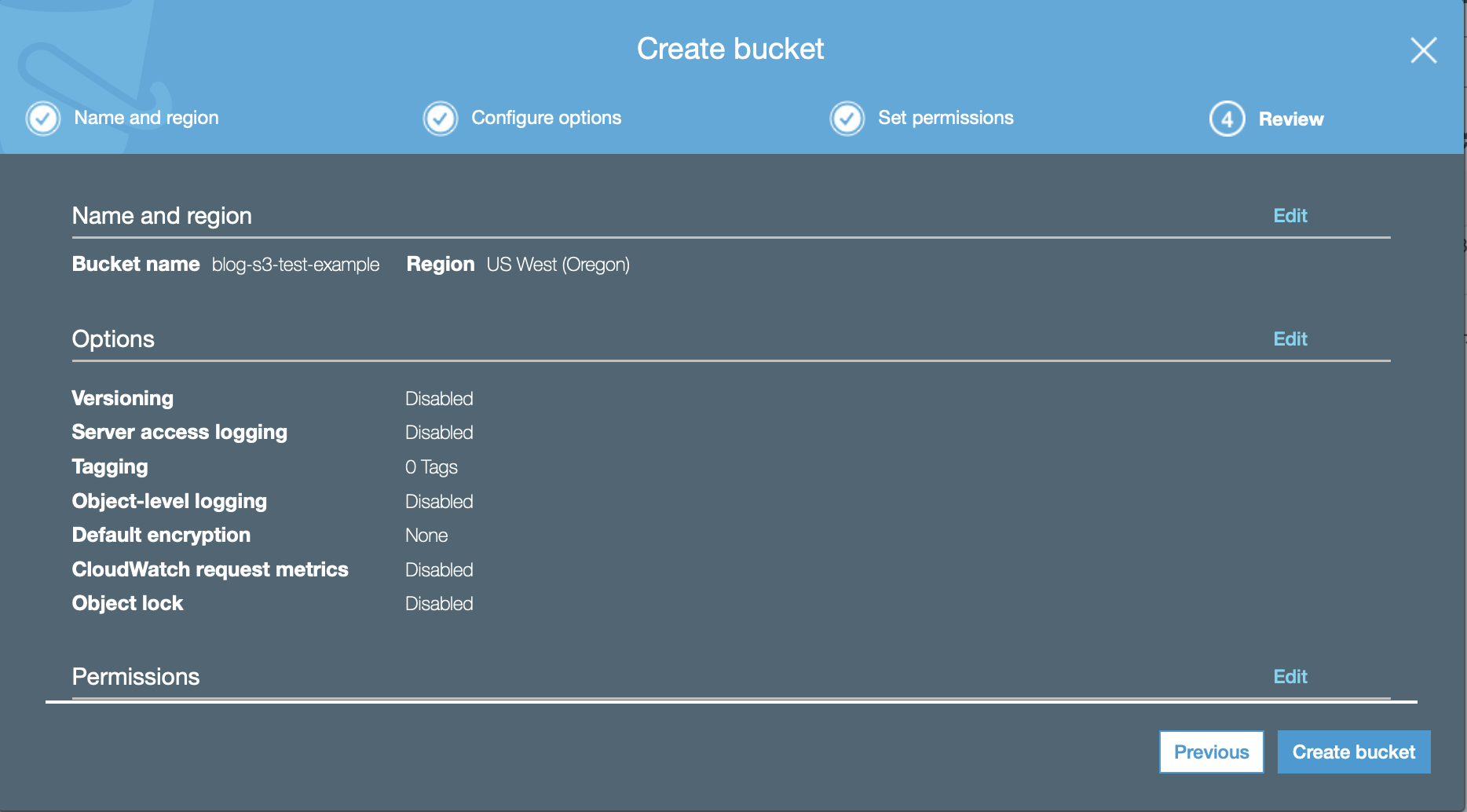
S3 Bucket Step 6:
Back on the S3 console you will now see the new bucket including that it is private, and in the US West region
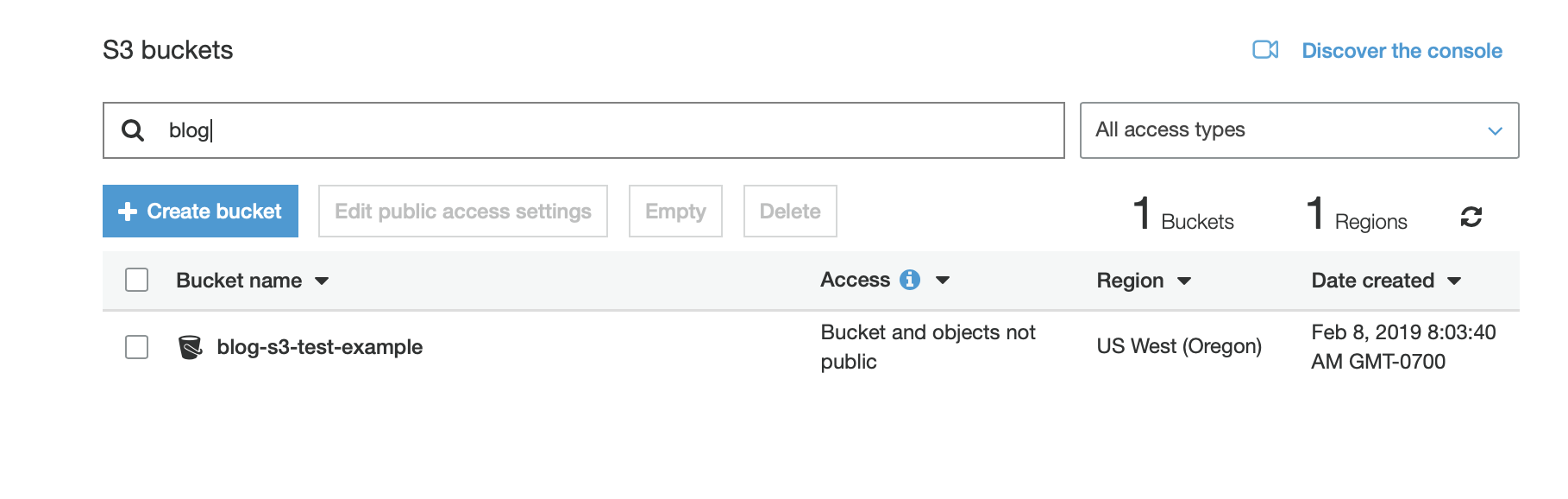
Let’s get to the fun part in R:
For the remainder of this post we will use R to:
- create a csv file
- connect to AWS and populate the S3 bucket we just created with the csv
- load the csv we added to S3 into a table in Athena
- then pull that data out of Athena back into R
We will use the following packages:
- tidyverse (CRAN)
- here (CRAN)
- knitr (CRAN)
- kableExtra (CRAN)
- mobstr (github) remotes::install_github(“themechanicalbear/mobstr”)
knitr::opts_chunk$set(message = FALSE, eval = FALSE,
tidy.opts = list(width.cutoff = 100))
suppressWarnings(suppressMessages(suppressPackageStartupMessages({
library_list <- c("tidyverse", "here", "mobstr", "knitr", "kableExtra")
lapply(library_list, require, character.only = TRUE)})))
Add AWS Credentials to .Rprofile:
Open your .Rprofile and add the following with the values specific to your account we created above.
This will allow your scripts to connect to AWS resources without having to include your keys in the scripts themselves
Sys.setenv("AWS_ACCESS_KEY_ID" = "YOUR_AWS_ACCESS_KEY_ID",
"AWS_SECRET_ACCESS_KEY" = "YOUR_AWS_SECRET_ACCESS_KEY",
"AWS_DEFAULT_REGION" = "us-west-2") # Whatever region your S3 bucket you created is in
- The mobstr package includes the write_2_S3 function to write stock data to AWS S3 for analysis.
- We can use this function to write any csv file we want.
- First let’s create a sample csv to upload
- Here I am saving this file to the static data directory to be included in the blog folder structure you don’t need to do that
- Let’s use the mtcars dataset to create a sample csv to upload
Athena requires there only be one csv per folder/bucket so the write_2_S3 function will create a new folder inside our blog-s3-test-example bucket to place our csv inside
readr::write_csv(mtcars, paste0(here::here(), "/static/data/mtcars.csv"))
mobstr::write_2_S3(file = "mtcars",
path = paste0(here::here(), "/static/data/"),
bucket = "blog-s3-test-example")
Check AWS S3 for our file!
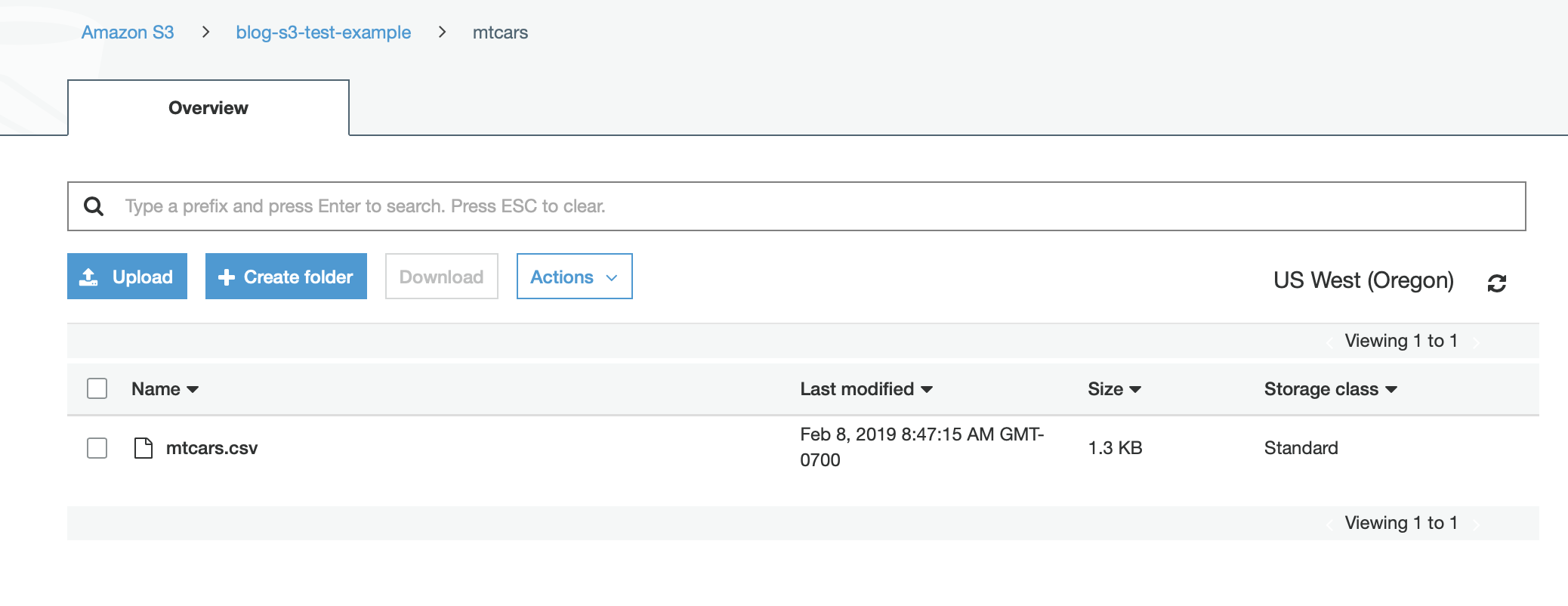
Create the table in Athena
- The mobstr package includes the athena_connect function to connect to the Athena service providing the database name. We are going to use the default database here.
- The mobstr package also includes the athena_load function which will use the connection to populate out table
- athena_load uses the following arguments:
- conn - The odbc connection created with athena_connect
- database - The database name
- s3_bucket - The name of our S3 bucket
- name - The name we want to assign to the table we are creating
- df - The dataframe name we are extracting the column names and types from
(if you don’t have mtcars available in your environment you need to load it with data(mtcars)) or read in whatever csv you loaded to S3 instead so they match
athena <- mobstr::athena_connect("default")
mobstr::athena_load(athena, "default", "blog-s3-test-example", "mtcars", mtcars)
mobstr Function Code:
- This package is in development as Mechanical Options Backtesting System w/ Tidy R (mobstr) so I’ll include the code here so that you will not need to load the package to follow this process.
# mobstr::write_2_S3
write_2_S3 <- function(file, path, bucket) {
file_path <- paste0(path, file, ".csv")
file_name <- paste0(file, ".csv")
bucket_name <- paste0(bucket, "/", file)
region_name <- Sys.getenv("AWS_S3_REGION")
aws.s3::put_bucket(bucket_name)
aws.s3::put_object(file = file_path,
object = file_name,
bucket = bucket_name,
region = region_name)
}
# mobstr::athena_connect
athena_connect <- function(database) {
DBI::dbConnect(
odbc::odbc(),
driver = Sys.getenv("AWS_ATHENA_DRIVER_FILE"),
Schema = database,
AwsRegion = Sys.getenv("AWS_DEFAULT_REGION"),
UID = Sys.getenv("AWS_ACCESS_KEY_ID"),
PWD = Sys.getenv("AWS_SECRET_ACCESS_KEY"),
S3OutputLocation = Sys.getenv("AWS_ATHENA_S3_OUTPUT")
)
}
# mobstr::athena_load
athena_load <- function(conn, database, s3_bucket, name, df) {
table_vars <- paste0("`", names(df), "` ", sapply(df, typeof), ",", collapse = '')
table_vars <- sub(",$", "", table_vars)
# SQL create table statement in Athena
DBI::dbExecute(conn, paste0("CREATE EXTERNAL TABLE IF NOT EXISTS ",
database, ".", name, " (", table_vars, " )",
"ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'",
"WITH SERDEPROPERTIES ('serialization.format' = ',', 'field.delim' = ',' )",
"LOCATION 's3://", s3_bucket, "/", name, "/'",
"TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1');"))
}
That’s It, did it work?…..
We can now connect read the table and bring the data back into R and View
athena_cars <- mobstr::athena_connect("default") %>%
dplyr::tbl("mtcars") %>%
dplyr::filter(mpg >= 25) %>%
dplyr::collect()
knitr::kable(athena_cars, digits = 2, format = "html",
caption = "Athena Cars",
col.names = c("MPG", "CYL", "DISP", "HP", "DRAT", "WT", "QSEC",
"VS", "AM", "GEAR", "CARB"),
escape = FALSE,
align = rep("r", 11)) %>%
kableExtra::kable_styling(., bootstrap_options = "striped", position = "center",
full_width = FALSE) %>%
kableExtra::column_spec(., 1:11, width = "1.5in")
| MPG | CYL | DISP | HP | DRAT | WT | QSEC | VS | AM | GEAR | CARB |
|---|---|---|---|---|---|---|---|---|---|---|
| 32.4 | 4 | 78.7 | 66 | 4.08 | 2.20 | 19.47 | 1 | 1 | 4 | 1 |
| 30.4 | 4 | 75.7 | 52 | 4.93 | 1.62 | 18.52 | 1 | 1 | 4 | 2 |
| 33.9 | 4 | 71.1 | 65 | 4.22 | 1.84 | 19.90 | 1 | 1 | 4 | 1 |
| 27.3 | 4 | 79.0 | 66 | 4.08 | 1.94 | 18.90 | 1 | 1 | 4 | 1 |
| 26.0 | 4 | 120.3 | 91 | 4.43 | 2.14 | 16.70 | 0 | 1 | 5 | 2 |
| 30.4 | 4 | 95.1 | 113 | 3.77 | 1.51 | 16.90 | 1 | 1 | 5 | 2 |
If you have suggestions or any other feedback please reach out with the contact links on the sidebar